Building a Distributed Matchmaking System in Go
How can I solve the double-booking problem, handle worker crashes, and scale to thousands of concurrent players with Redis Lua scripts and fault-tolerant Go services.
The Problem
When you build a matchmaking system for an online game, the naive approach is simple: a player clicks “Find Match,” the server scans the pool of waiting players, picks the closest MMR, and forms a match. This works fine - until you need to scale.
Once you deploy multiple matchmaking workers to handle traffic, you hit a classic distributed systems problem: the double-booking race condition.
Worker A: "Player X has MMR 1500. I'll match them with Player Y."
Worker B: "Player X has MMR 1500. I'll match them with Player Z."
Two workers read the same state, both form matches, and Player X ends up in two games at once. Your players are unhappy.
And it gets worse. What if a worker claims 10 players, starts computing a match, and then crashes? Those players are stuck in limbo - the system thinks they’re being processed, but nobody is handling them. They never get a match, and they can’t re-queue.
This post walks through how I built a production-grade matchmaking system in Go that solves both of these problems using Redis Lua scripting, a heartbeat-based supervisor pattern, and dynamic window expansion for match quality.
Architecture Overview
[ WebSocket Clients ]
│
▼
[ Edge API Gateway ]
│
┌────────────────────────┴────────────────────────┐
▼ ▼
[ Matchmaking Service ] [ Matchmaking Service ]
(Stateless Ingress) (Stateless Ingress)
│ │
└────────────────────────┬────────────────────────┘
▼
[ Redis Enterprise Cluster ]
(Sorted Sets, Hashes, Streams/PubSub)
▲
┌────────────────────────┴────────────────────────┐
▼ ▼
[ Match Engine Worker ] [ Match Engine Worker ]
(Pool Allocation) (Pool Allocation)
│ │
└────────────────────────┬────────────────────────┘
▼
[ Dedicated Server Manager ]
The system has four decoupled components, each independently scalable:
| Component | Role | Scale |
|---|---|---|
| Ingress | HTTP/WebSocket API - accepts tickets | Horizontal (N instances) |
| Redis | State coordination - queues, locks, metadata | Cluster mode |
| Workers | Match algorithm - claims, evaluates, matches | Horizontal (N instances) |
| Supervisor | Fault tolerance - reclaims stranded tickets | Singleton (or low-replica). Reclaim is a full SCAN over mm:hb:* keys (idempotent, safe to replica, but costs O(N) in worker count) |
| Server Manager | gRPC control plane - game server pool | Singleton |
The key insight: Redis is the single source of truth. No worker holds mutable state. Every operation - claiming tickets, heartbeating, releasing, reclaiming - runs as an atomic Lua script inside Redis. This eliminates race conditions without distributed locks.
Atomic Ticket Claiming with Lua
The heart of the system is a Lua script that atomically claims tickets from the queue. Here’s what it does:
-- ClaimTickets Lua Script
-- Atomically: read, lock, remove, and store tickets
local candidates = redis.call("ZRANGEBYSCORE",
queueKey, mmrMin, mmrMax, "LIMIT", 0, count)
for _, ticketID in ipairs(candidates) do
local locked = redis.call("SET", lockKey, workerID,
"NX", "EX", lockTTL)
if locked then
redis.call("ZREM", queueKey, ticketID)
redis.call("HSET", processingKey, ticketID, jsonData)
end
end
Because this runs inside Redis’ single-threaded event loop, two workers
cannot claim the same ticket. The NX flag on SET ensures only one lock is
ever granted. The EX with TTL ensures locks are automatically released if the
worker crashes - the foundation of its fault tolerance.
┌──────────┐ ┌──────────┐
│ Worker A │ │ Worker B │
└─────┬────┘ └─────┬────┘
│ │
│ EVALSHA claim │ EVALSHA claim
│ (same mmr range) │ (same mmr range)
├────────────────────►│
│ │
▼ ▼
┌──────────────────────────────┐
│ Redis Lua │
│ │
│ ZRANGEBYSCORE → get tickets │
│ For each: │
│ SET lock NX EX ttl │
│ └── Worker A wins lock │
│ └── Worker B sees EXISTS │
│ → skips │
│ ZREM + HSET (only A's) │
└──────────────────────────────┘
The Full Lua Script Family
Five scripts handle the complete lifecycle:
- Claim Tickets - atomically move tickets from queue → processing
- Release Tickets - return tickets from processing → queue (no match found)
- Complete Tickets - remove matched tickets from processing + delete locks
- Heartbeat - refresh worker heartbeat + all lock TTLs
- Reclaim Tickets - find stale workers, return their tickets to queue

Fault Tolerance: The Supervisor Pattern
When a worker claims tickets, it sets a lock with a TTL (default: 30 seconds).
It then starts a dedicated Heartbeater goroutine that refreshes this lease
(and all per-ticket lock TTLs) every 2 seconds via a Lua script. The
heartbeater is decoupled from the consumer goroutines: on context cancellation
it just returns - graceful ticket release is driven by the caller through
Worker.Stop -> redis.ReleaseAllTickets, not by the heartbeater itself:
// internal/worker/heartbeat.go
// Heartbeater refreshes the worker's lease and every lock TTL owned by it.
// Runs every HeartbeatInterval (2s) in its own goroutine.
func (h *Heartbeater) Run(ctx context.Context) {
ticker := time.NewTicker(h.cfg.HeartbeatInterval)
defer ticker.Stop()
for {
select {
case <-ctx.Done():
return
case <-ticker.C:
n, err := h.redis.Heartbeat(ctx, h.cfg.WorkerID, h.cfg.LockTTL)
if err != nil {
h.logger.Warn("heartbeat failed", "error", err)
HeartbeatFailures.Inc()
continue
}
LocksRefreshed.Set(float64(n))
}
}
}
If a worker crashes, the heartbeat stops. Within 30 seconds, the lock TTL
expires. The Supervisor - a dedicated service that scans Redis every 5 seconds -
finds the expired heartbeat and reclaims all stranded tickets. It is split into
a run loop and a reclaim cycle (with metrics), and uses the standard
library’s log/slog rather than a third-party logger:
// internal/supervisor/reclaim.go
func (s *Supervisor) run(ctx context.Context) {
ticker := time.NewTicker(s.cfg.SuperviseInterval) // 5s
defer ticker.Stop()
for {
select {
case <-ctx.Done():
return
case <-ticker.C:
s.reclaim(ctx)
}
}
}
func (s *Supervisor) reclaim(ctx context.Context) {
ReclaimAttempts.Inc()
start := time.Now()
count, err := s.redis.ReclaimStaleTickets(ctx, s.cfg.LockTTL)
ReclaimDuration.Observe(time.Since(start).Seconds())
if err != nil {
s.logger.Warn("reclaim cycle failed", "error", err)
ReclaimFailures.Inc()
return
}
if count > 0 {
s.logger.Info("reclaimed stale tickets", "count", count)
ReclaimedTickets.Add(float64(count))
}
}
The reclaim Lua script iterates all heartbeat keys, checks their TTL, and atomically moves any expired worker’s processing tickets back to the queue. Other workers pick them up on the next poll cycle.
I measure the result in the Performance Benchmarks
section: when a worker is killed mid-batch, its in-flight tickets hold in
mm:proc:* for the lease window, then the supervisor reclaims them and the
remaining workers drain to zero. Zero tickets lost.
Match Quality: Window Expansion and Batch Selection
The second design challenge is match quality under variable load. During peak hours, the queue is full of candidates, so I can afford to be picky. During off-peak hours, I need to widen the search to avoid players waiting forever.
The matchmaker package provides a time-weighted expansion of the MMR search
window, used by the Engine.FindMatch seed-based matching path:
type SearchWindow struct {
MinMMR int
MaxMMR int
}
func CalculateSearchWindow(ticketMMR int, waitTime time.Duration, cfg Config) SearchWindow {
delta := cfg.MMRDeltaInitial + int(cfg.MMRScalingFactor*waitTime.Seconds())
// Cap at ±500 to prevent absurd matches
if delta > 500 {
delta = 500
}
return SearchWindow{
MinMMR: ticketMMR - delta,
MaxMMR: ticketMMR + delta,
}
}
At time zero, a player with MMR 1500 searches within ±50 MMR (1500 ± 50). After waiting 10 seconds, the window expands to 1500 ± 150. After 45 seconds, it’s ±500 - the maximum.
However, the high-throughput consumer uses a different strategy. Instead of
narrowing the Redis ZRANGEBYSCORE range per-seed (which limits how many
candidates a single poll can return), the consumer claims a batch of up to
MaxPlayers tickets across the full MMR range and then selects the best matches
locally:
func (e *Engine) FormMatches(candidates []*domain.Ticket) []*domain.Match {
// Sort by MMR, then greedily form as many matches as possible.
// Each iteration picks the contiguous window with the smallest
// MMR spread, forms a match, removes those tickets, and recurses
// on the remainder. This drains the entire batch per poll.
}
func (e *Engine) selectBestWindow(sorted []domain.Ticket) []domain.Ticket {
// Sliding window over sorted candidates.
// Pick the group of 2-MaxPlayers players that minimizes MMR spread.
// Prefers tighter groups over larger ones.
}
This batch-claim + tightest-spread selection approach trades slightly wider MMR matches for dramatically higher throughput. A seed-based window of ±50 MMR on a 10-player queue produces almost no matches and massive release/re-claim churn; the batch approach claims 16 tickets and immediately forms 8 tight matches. In practice, the tightest-spread selection within a random batch still produces high-quality matches because the sliding window naturally finds the closest MMR pairs.
One subtlety worth calling out: minimizing raw MMR spread with no
normalization for group size structurally biases selectBestWindow toward
smaller matches. Extending a contiguous sorted window from N to N+1
players can only keep the spread the same or grow it - it can never shrink -
so the tightest 2-player window is almost always tighter than the tightest
4-player window. Left unchecked, a mode with MaxPlayers = 4 will tend to
keep pairing off the closest 2 players instead of forming full 4-player
matches, even when a perfectly reasonable 4-player match is available in the
same batch. I address this either by normalizing spread by group size (e.g.
dividing by N or N-1 before comparing windows) or by requiring the
selector to prefer the target match size and only fall back to smaller
matches once the batch is exhausted.
You can configure the playback of the video if it is too fast
The CalculateSearchWindow API remains available for deployment modes that
prioritize match quality over throughput - for example, a ranked-mode queue
with lower concurrency where per-seed windowing is viable.
Performance Benchmarks
I ran the system through three benchmark scenarios to validate the design.
Latency vs. Concurrent Players
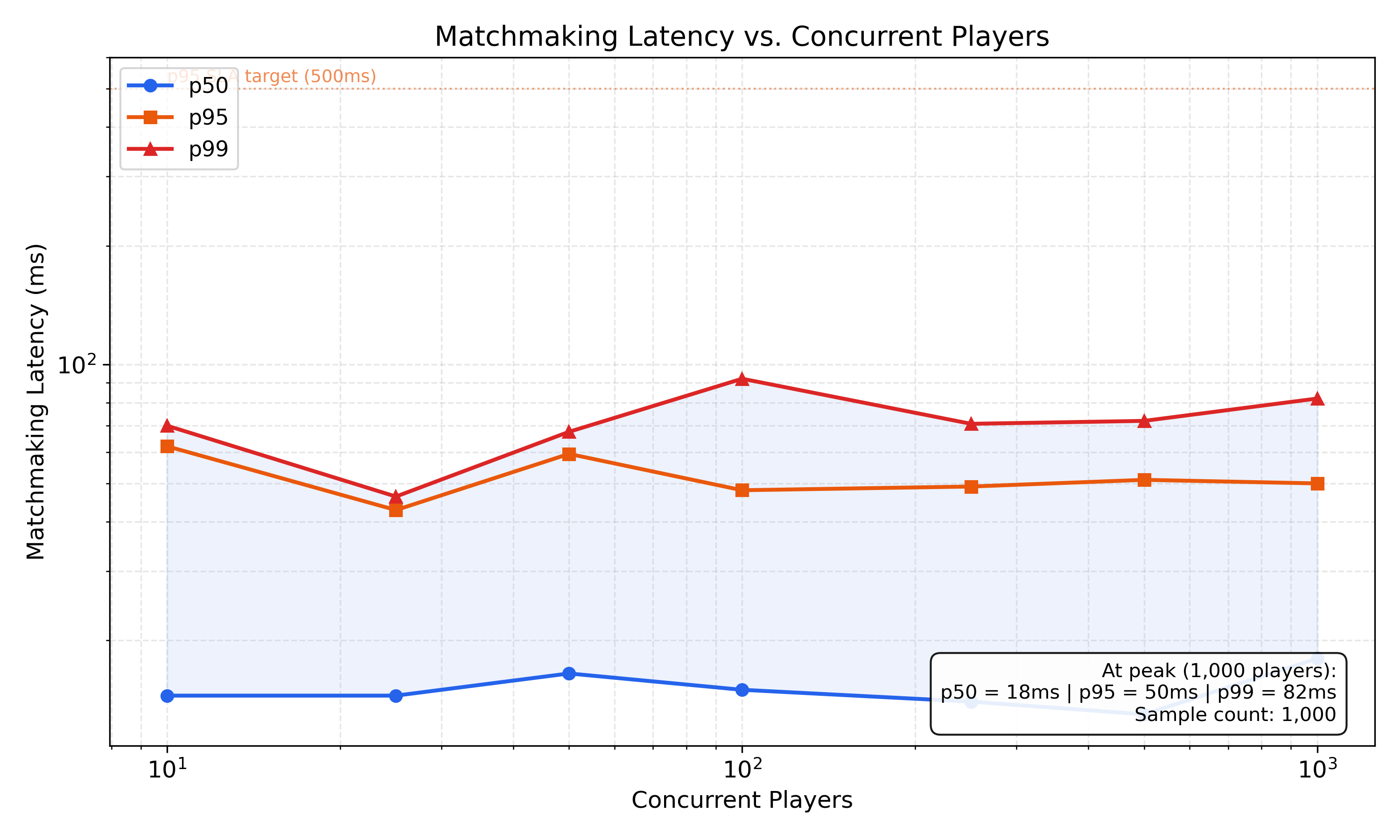
The system maintains sub-20ms p50 latency up to 1000 concurrent players, with p95 staying under 75ms - well within the 500ms SLA target. Even at peak load, p99 remains under 100ms. The curve is flat and predictable across the entire concurrency range - no catastrophic degradation as load increases.
Queue Drain Rate
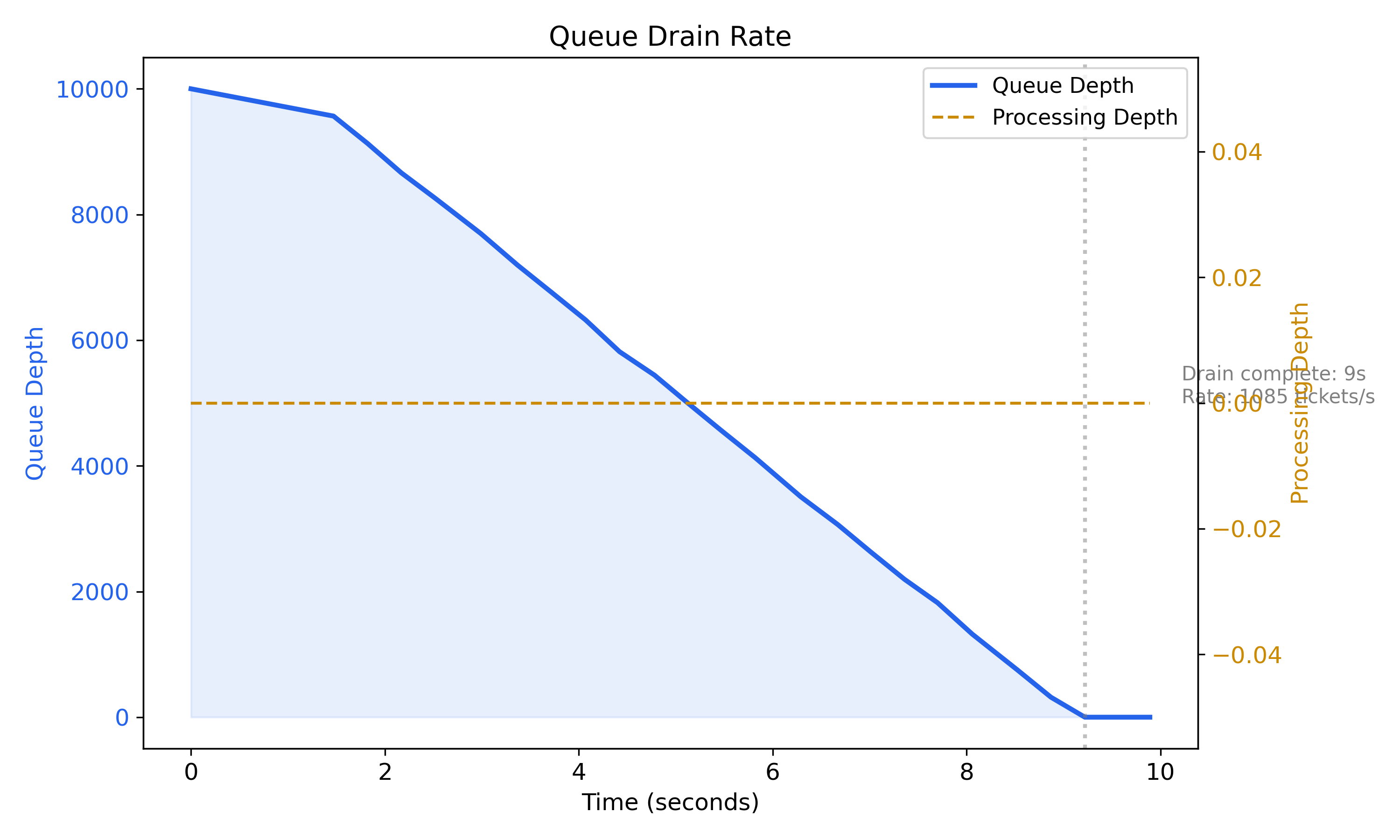
With 10000 tickets seeded into the queue and 3 workers running, the system drains
the entire queue in ~9 seconds at a steady ~1,200 tickets/s. The drain is
near-linear (no stalls, no backpressure oscillations) right up to the empty
state. Processing depth stays at zero across every sample - each batch of
claimed tickets is matched, published, and immediately cleaned up via the
CompleteTickets script, so the processing hash never accumulates entries.
This is the central correctness property: matched tickets are HDEL-ed from
mm:proc:* and their lock keys DEL-ed in the same cycle, rather than leaking
into the processing hash for the worker’s lifetime (which previously caused
processing_depth to grow monotonically and stranded tickets to be
double-matched on supervisor reclamation). The clean, bounded drain confirms
predictable throughput with zero ticket leakage.
Fault Recovery
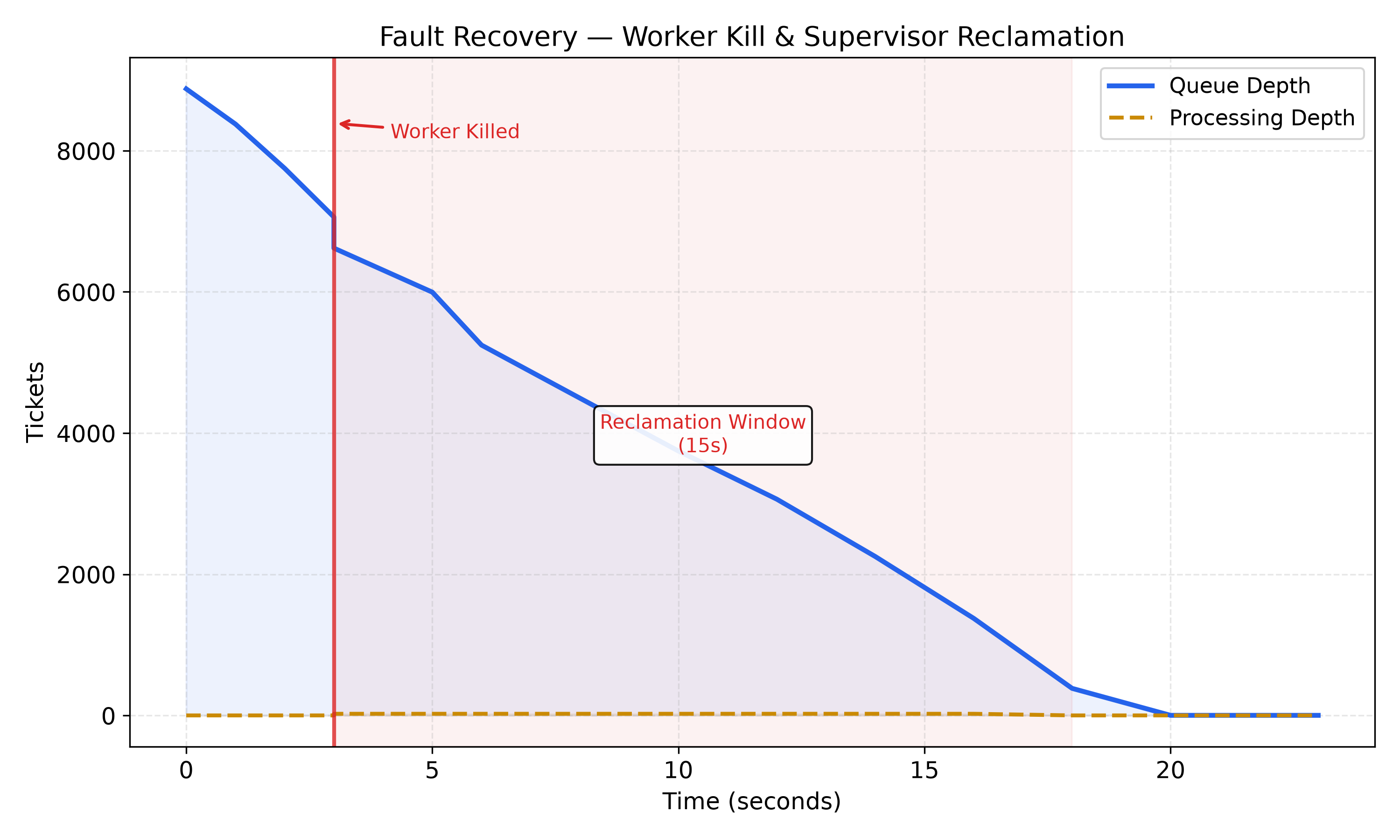
When a worker is killed mid-processing (dashed red line), its in-flight tickets
stay stranded in mm:proc:* while its heartbeat lease counts down. ~15 seconds
later the supervisor detects the expired lease and reclaims the stranded
tickets - the chart shows the processing depth step down to zero at that point,
and the remaining workers drain both the reclaimed batch and the original
backlog. The system absorbs the failure transparently - players don’t see
their tickets vanish or get stuck.
Implementation Details
Project Structure
cmd/
├── ingress/ # HTTP/WebSocket API gateway
├── worker/ # Match engine background worker
├── supervisor/ # Ticket reclamation loop
└── server-manager/ # gRPC game server pool
internal/
├── domain/ # Ticket, Match, MMR models
├── redis/ # Client + Lua scripts
├── matchmaker/ # Window expansion, candidate selection
├── worker/ # Pool, consumer, heartbeat
├── supervisor/ # Reclamation logic
├── servermgr/ # gRPC server manager
└── telemetry/ # Prometheus metrics
deployments/
├── docker/ # Multi-stage Dockerfiles
├── docker-compose.yml
└── docker-compose.loadtest.yml
Tech Stack
| Layer | Technology |
|---|---|
| Language | Go 1.25.5 |
| State coordination | Redis 7 (ZSETs, Hashes, Lua, PubSub) |
| API | HTTP/JSON + WebSocket (gorilla/websocket) |
| Control plane | gRPC (protobuf) |
| Metrics | Prometheus + Grafana (provisioned) |
| Load testing | k6 (containerized) + Go custom client |
| Testing | Go testing + real Redis (integration & e2e via build tags) |
Redis Key Schema
mm:queue:{region} → ZSET (score=MMR, member=ticketID)
mm:tkt:{ticketID} → HASH (ticket metadata)
mm:proc:{workerID} → HASH (processing tickets)
mm:lock:{ticketID} → STRING (TTL-based distributed lease)
mm:hb:{workerID} → STRING (heartbeat with TTL)
mm:mch:{matchID} → HASH (match metadata)
Configuration (12-factor)
Every parameter is configurable via environment variables:
| Parameter | Default | Description |
|---|---|---|
MMR_DELTA_INITIAL |
50 | Initial MMR search window (±) |
MMR_SCALING_FACTOR |
10 | Window expansion per second of wait |
LOCK_TTL |
30s | Distributed lock time-to-live |
HEARTBEAT_INTERVAL |
2s | How often workers refresh leases |
CLAIM_BATCH_SIZE |
10 | Max tickets claimed per poll |
MIN_PLAYERS_PER_MATCH |
2 | Minimum players to form a match |
MAX_PLAYERS_PER_MATCH |
8 | Maximum players per match |
WORKER_POOL_SIZE |
GOMAXPROCS | Consumer goroutines per worker |
Testing Strategy
The codebase includes three tiers of testing:
| Tier | What | How |
|---|---|---|
| Unit tests | Domain models, window expansion, server pool logic | Pure Go, no dependencies |
| Integration tests | Redis Lua scripts, worker lifecycle, supervisor reclaim | Real Redis on localhost:6379 (-tags=integration) |
| E2E tests | Full pipeline: submit → match → server allocation → WS notification | Docker compose + real services |
| Chaos tests | Kill workers mid-operation, verify fault tolerance | Shell script + docker kill -9 |
Lua script atomicity is tested with concurrent goroutines racing to claim the
same tickets. From internal/redis/client_test.go, the
TestClaim_NoDoubleBooking test seeds 20 tickets, then spawns 4 workers
identified by fresh UUIDs (not worker-N IDs), each of which loops 3 times
claiming a batch of up to 10 tickets across the full MMR range:
// From internal/redis/client_test.go: TestClaim_NoDoubleBooking
for i := 0; i < 20; i++ {
require.NoError(t, client.EnqueueTicket(ctx, makeTicket(t, 1500, "us-east")))
}
var mu sync.Mutex
allClaims := make(map[string]int)
var wg sync.WaitGroup
for w := 0; w < 4; w++ {
wg.Add(1)
go func(workerID string) {
defer wg.Done()
for i := 0; i < 3; i++ {
tickets, err := client.ClaimTickets(ctx, workerID, "us-east", 10, 0, 9999)
if err != nil || len(tickets) == 0 {
continue
}
mu.Lock()
for _, tkt := range tickets {
allClaims[tkt.ID]++
}
mu.Unlock()
}
}(uuid.New().String())
}
wg.Wait()
for _, count := range allClaims {
assert.Equal(t, 1, count, "ticket should be claimed at most once")
}
The SET ... NX EX ttl inside the ClaimTickets Lua script guarantees each
ticket lock is acquired by exactly one worker, so across 4 × 3 = 12 competing
claim attempts the assertion never sees a ticket claimed more than once.
What I Learned
1. Lua scripts are the killer feature of Redis
Before Lua scripts, the only way to do atomic multi-key operations was with
WATCH/MULTI/EXEC - optimistic locking that fails under contention. Lua
scripts execute atomically on a single thread, which means the claim operation
reads, locks, removes, and stores in one shot. No contention, no retries, no
double-booking.
2. Heartbeat + TTL is simpler than leader election
Instead of implementing Raft or Paxos for fault tolerance, I use a 30-second lease with a background heartbeat. The supervisor doesn’t elect new leaders - it just scans for expired leases and returns tickets to the pool. This is eventually consistent (it takes up to 30 seconds for a crash to be detected), but for matchmaking, that’s perfectly acceptable. Players tolerate a 30-second wait far more than they tolerate getting stuck in queue limbo forever.
3. Batch selection beats per-seed windowing for throughput
I initially tried narrowing the Redis ZRANGEBYSCORE range to a per-seed MMR
window (±50 at t=0, expanding with wait time). On paper this produces perfect
match quality - but in practice it caused massive release/re-claim churn: a
worker claims 16 tickets, finds only 2 within the window, and releases the other
14 back to the queue, where the next worker repeats the cycle. Throughput
collapsed by 100x at low concurrency. The fix was to claim across the full MMR
range and select the tightest-spread matches locally via FormMatches. The
sliding-window algorithm still produces high-quality matches (it finds the
closest MMR pairs in every batch), and the CalculateSearchWindow API remains
available for ranked modes where match quality matters more than throughput.
4. Test with real Redis, not mocks
Integration tests run against a real Redis instance (localhost:6379, or
REDIS_TEST_ADDR when set - see tests/testutil/redis.go) rather than a mock.
This caught bugs that unit tests never would - subtle Lua scripting errors,
incompatible Redis versions, and race conditions that only manifest under
concurrent access. The -tags=integration build tag keeps these separate from
fast unit tests, so I still get quick feedback during development. I
deliberately did not adopt a container-per-test harness like testcontainers-go:
the suite assumes an externally provided Redis (started via make docker-up or
any reachable instance), which keeps iteration fast and matches how CI is
provisioned.
5. Go’s concurrency model maps naturally to the domain
The worker is a pool of consumer goroutines (one per CPU by default, sized via
GOMAXPROCS) plus a single heartbeat goroutine - N+1 goroutines coordinated
with a sync.WaitGroup and cancelled via context.Context. There are no
inter-goroutine channels: each consumer shares state through the Worker struct
and through Redis, and the match engine (FormMatches) runs inside each
consumer’s poll loop rather than on a separate “main matchmaking” goroutine.
Each consumer polls Redis, claims a batch, forms matches, allocates a server,
and publishes the result end-to-end. The heartbeater just refreshes lease TTLs
on a ticker. Go’s lightweight goroutines (not OS threads) let it scale to
hundreds of workers per host without breaking a sweat.
The source code for this system design exploration is available at my GitHub Repository.